Thomas Dramab과 Denny Lee의 “Learning PySpark”를 보면서 학습 과정을 기록한 기록입니다♪
.count(…) 함수
– 항목 수를 계산
>>> data_reduce = sc.parallelize((1, 2, .5, .1, 5, .2), 3)>>> data_reduce.count()
6→ 6개 이상의 요소수에 따라 출력
.saveAsTextFile(…) 함수
'추천 관련글,



– RDD를 텍스트 파일로 저장
– 별도의 파일에 각 파티션!
>>> data_key = sc.parallelize(
... (('a', 4), ('b', 3), ('c', 2), ('a', 8), ('d', 2), ('b', 1), ('d', 3)), 4)>>> data_key.saveAsTextFile('/Users/hayeon/Downloads/data_key.txt')
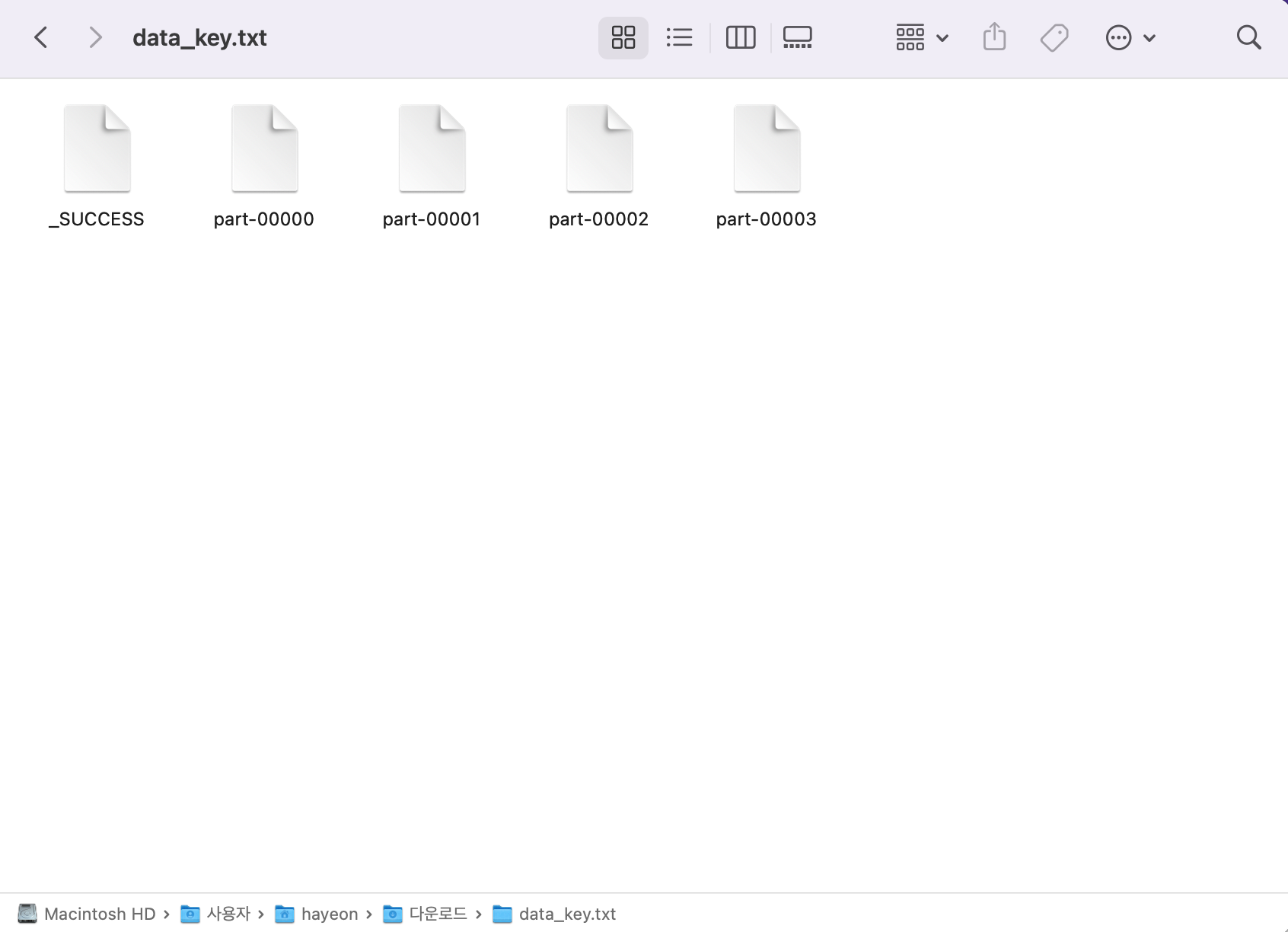
* _SUCCESS : 내용이 없는 파일로 성공적으로 저장되었음을 나타냄
* part-00000: (‘a’, 4), data_key의 첫 번째 파티션 값
* part-00001: data_key의 두 번째 파티션 값 (‘b’, 3), (‘c’, 2)
* part-00002: (‘a’, 8), (‘d’, 2), data_key의 세 번째 파티션 값
* part-00003: data_key의 4번째 파티션 값 (‘b’, 1), (‘d’, 3)
– 각 행은 문자열로 표현되므로 거꾸로 읽으려면 역방향으로 파싱해야 합니다.
>>> def parseInput(row):
... import re
... pattern = re.compile(r'\(\'((a-z))\', ((0-9))\)')
... row_split = pattern.split(row)
... return (row_split(1), int(row_split(2)))>>> data_key_reread = sc.textFile('/Users/hayeon/Downloads/data_key.txt').map(parseInput)
>>> data_key_reread.collect()
(('a', 8), ('d', 2), ('b', 1), ('d', 3), ('b', 3), ('c', 2), ('a', 4))
.foreach(…) 함수
– RDD의 각 요소에 동일한 기능을 반복 적용
– .map() 함수와 달리 정의된 함수가 모든 데이터에 개별적으로 적용됨
– PySpark에서 지원하지 않는 DB에 데이터를 저장하려는 경우에 유용합니다.
ex) data_key RDD에 저장된 모든 데이터 출력
>>> def f(x):
... print(x)→ 간단한 데이터 출력 함수 생성
>>> data_key.foreach(f)
('a', 8)
('d', 2)
('b', 3)
('c', 2)
('b', 1)
('d', 3)
('a', 4)→ 함수 f를 각 요소에 적용한 결과 한 줄씩 출력되는 것을 볼 수 있습니다!